TL;DR:
Agent-R1 将 MDP 框架系统性延伸到 LLM Agent 的多轮工具调用场景,
构建了一套模块化、易扩展的端到端强化学习训练框架,
在多跳问答基准上,最优 RL 算法比 RAG 基线高出约 3 倍(EM 0.39 vs 0.13)。
项目简介
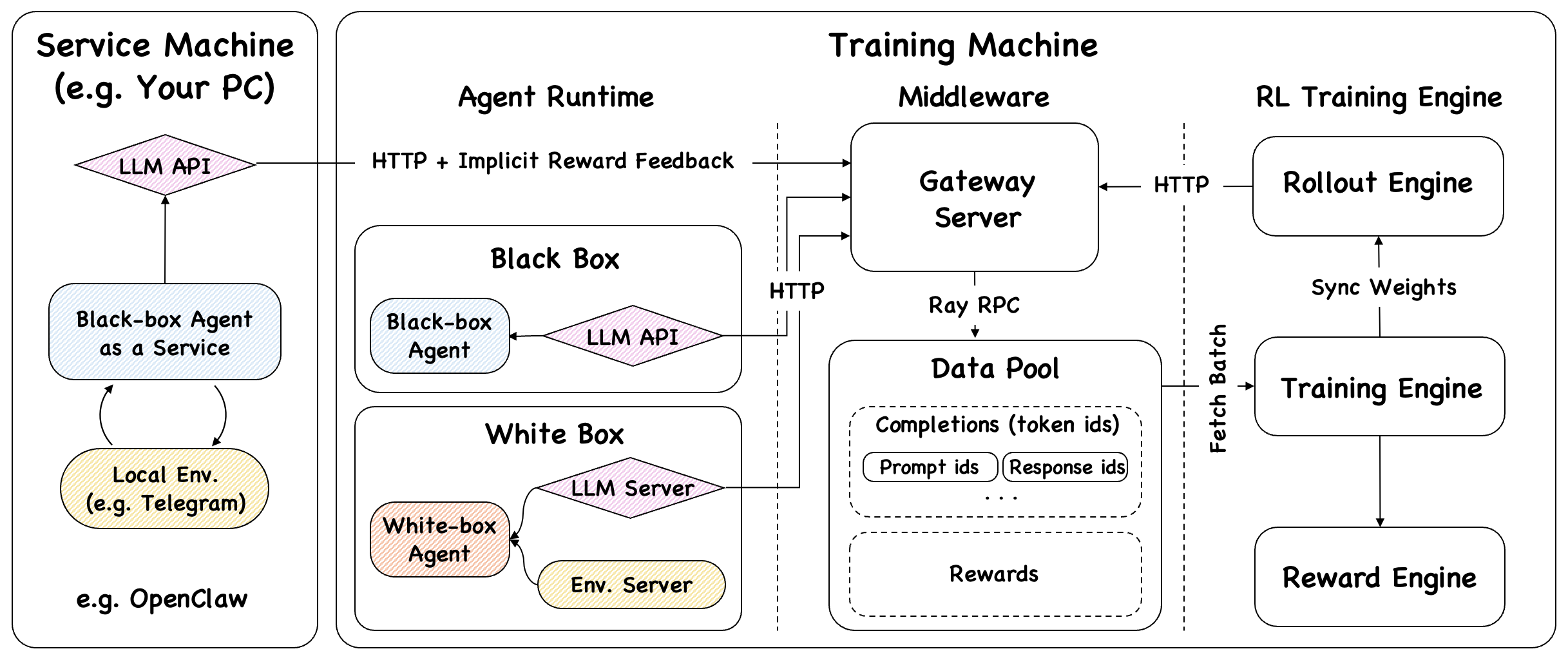
大语言模型(LLM)越来越多地被用于构建能与环境主动交互的 Agent——通过工具调用、多步推理解决复杂问题。 强化学习(RL)被认为是训练此类 Agent 的关键技术,但其有效应用仍处于早期阶段, 面临多轮交互不稳定、奖励信号设计复杂、泛化能力受限等独特挑战。
Agent-R1 从概念与实践两个维度系统性地回应了这些挑战: 一方面,对 RL 方法论在 LLM Agent 场景下的应用进行梳理与澄清; 另一方面,提供一个灵活、易用的端到端训练框架,开发者只需定义工具和奖励函数即可快速迁移到新场景。

~3×
优于 RAG 基线
(平均 EM)
(平均 EM)
5
支持 RL 算法
PPO / GRPO / REINFORCE++ 等
PPO / GRPO / REINFORCE++ 等
3
评测基准
HotpotQA / 2Wiki / Musique
HotpotQA / 2Wiki / Musique
✓
多模态支持
VLM + 多模态 RL
VLM + 多模态 RL