页面定位
Agent-R1 围绕 Getting Started、Core Concepts 和 Tutorials 三条主线组织内容。 这份页面优先聚焦最关键的阅读内容,方便第一次接触的人按顺序建立整体理解。
版本定位
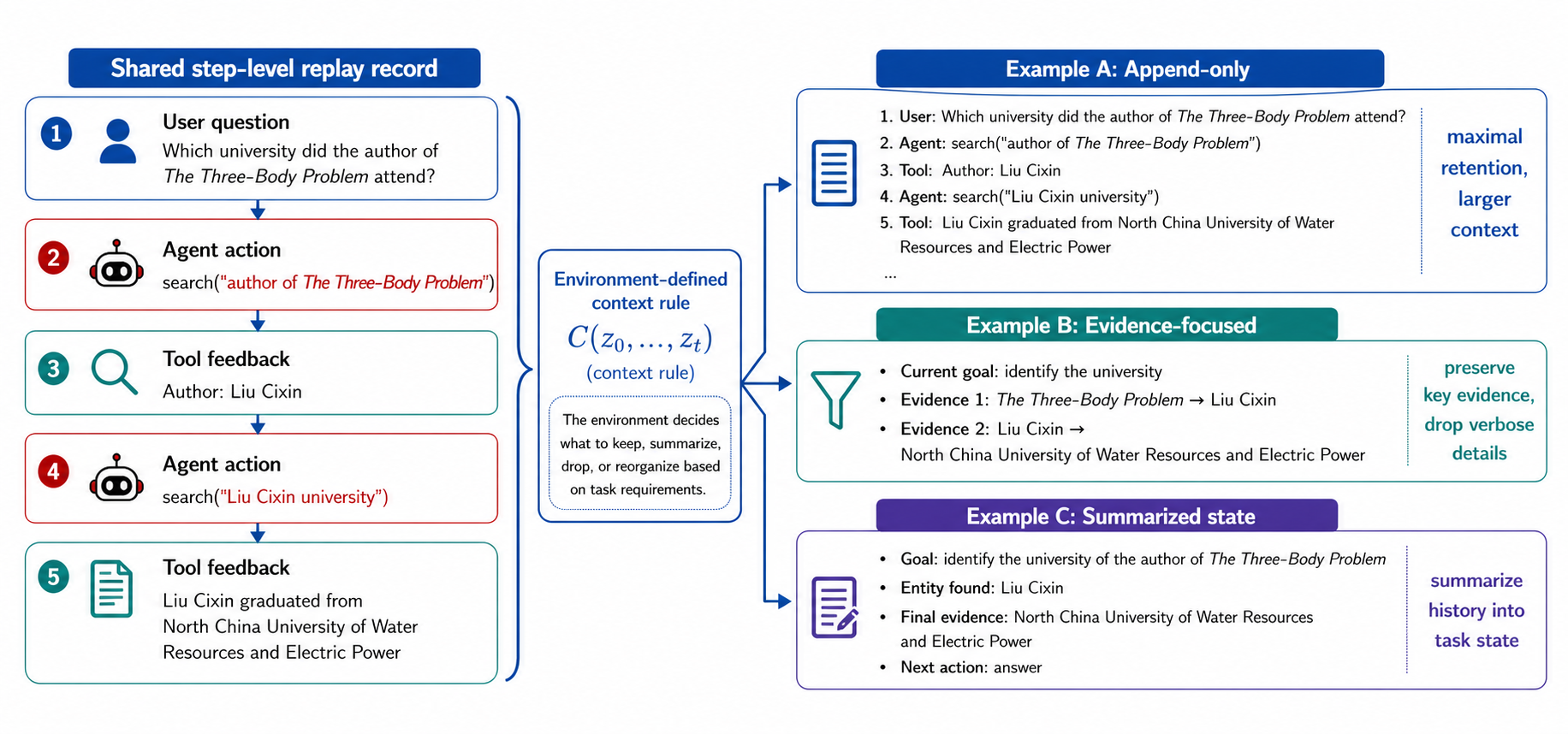
当前主线对应 Agent-R1 v0.1.0。这一版以 Step-level MDP 和
Layered Abstractions 为核心重构了整体架构;旧实现保留在
legacy 分支中,便于回溯参考。
适合谁读
第一次准备跑 Agent-R1 的使用者,或者想快速理解其训练抽象的研究者。
内容边界
优先讲清最核心结构和上手路径;更长的 API 细节和完整章节仍然保留在正式站点里作为补充。