OpenClaw 之后,Agentic RL 有了新训练范式
Claw-R1:将真实 Agent Runtime 与 RLVR 训练深度结合,
为下一代 Agentic AI 提供完整的强化学习训练基础设施。
中国科学技术大学 · 认知智能全国重点实验室
Claw-R1:将真实 Agent Runtime 与 RLVR 训练深度结合,
为下一代 Agentic AI 提供完整的强化学习训练基础设施。
中国科学技术大学 · 认知智能全国重点实验室
近年来,大模型技术的发展正在推动 AI 从「回答问题」逐渐迈向「执行任务」。 在 Agentic AI 的世界里,大模型不再只是文本生成器,而是通过调用工具、环境交互、 多步推理来执行复杂任务的智能体。
然而,当 Agent 能够在真实环境中运行时,一个新的问题随之出现: 我们应该如何训练这样的 Agent?
中国科大认知智能全国重点实验室提出的 Claw-R1 项目, 正是针对这一问题提出的全新强化学习训练框架。它尝试将前沿的 Agent Runtime(如 OpenClaw) 与强化学习训练框架深度结合,为 Agentic AI 提供全新的训练基础设施。
大模型强化学习正经历一次重要转变:从人类偏好学习(RLHF), 到任务结果学习(RLVR),再到环境交互学习(Runtime RL)。
| 阶段 | 目标 | 奖励来源 | 代表工作 |
|---|---|---|---|
| RLHF | 生成更符合人类偏好的文本 | Human preference | InstructGPT |
| RLVR | 完成可验证任务 | Verifiable reward | VERL、Agent-R1 |
| Runtime RL 本项目 | 在真实环境中行动 | Environment feedback | Claw-R1 |
总趋势:AI 的奖励来源正在越来越接近真实世界。
尽管 RLVR 已能支持多轮交互学习,但仍存在一个关键问题: Agent 运行环境并不真实。
目前大多数 RLVR 框架依赖研究导向的模拟环境:
这些都是特定任务的训练场,而非真实的 Agent Runtime。 模型从未真正运行在现实工具系统中,导致在真实 Agent 系统中出现 工具调用混乱、规划能力不足、长任务不稳定等问题。
OpenClaw 是一款开源的个人 AI Agent 操作系统(MIT 协议,TypeScript 实现,本地优先原则)。 自发布以来,8 周内获得超过 236,000 个 GitHub Star, 成为开源历史上增长最快的项目之一。
其核心架构采用 Hub-and-Spoke 设计:15+ 主流消息平台通过统一 Gateway 接入, 驱动中央的 Pi Agent Runtime 执行任务。Lane Queue 机制通过串行执行消除并发竞态条件, 三层混合记忆系统则为 Agent 提供稳定的上下文管理能力, 使 OpenClaw 成为第一个可在真实消息环境中自主、持续运行的 Agent 平台。
Claw-R1(OpenClaw-RL)构建了一个完整的 Agent Runtime + RLVR Training Loop 系统。 整体系统分为三个核心部分:
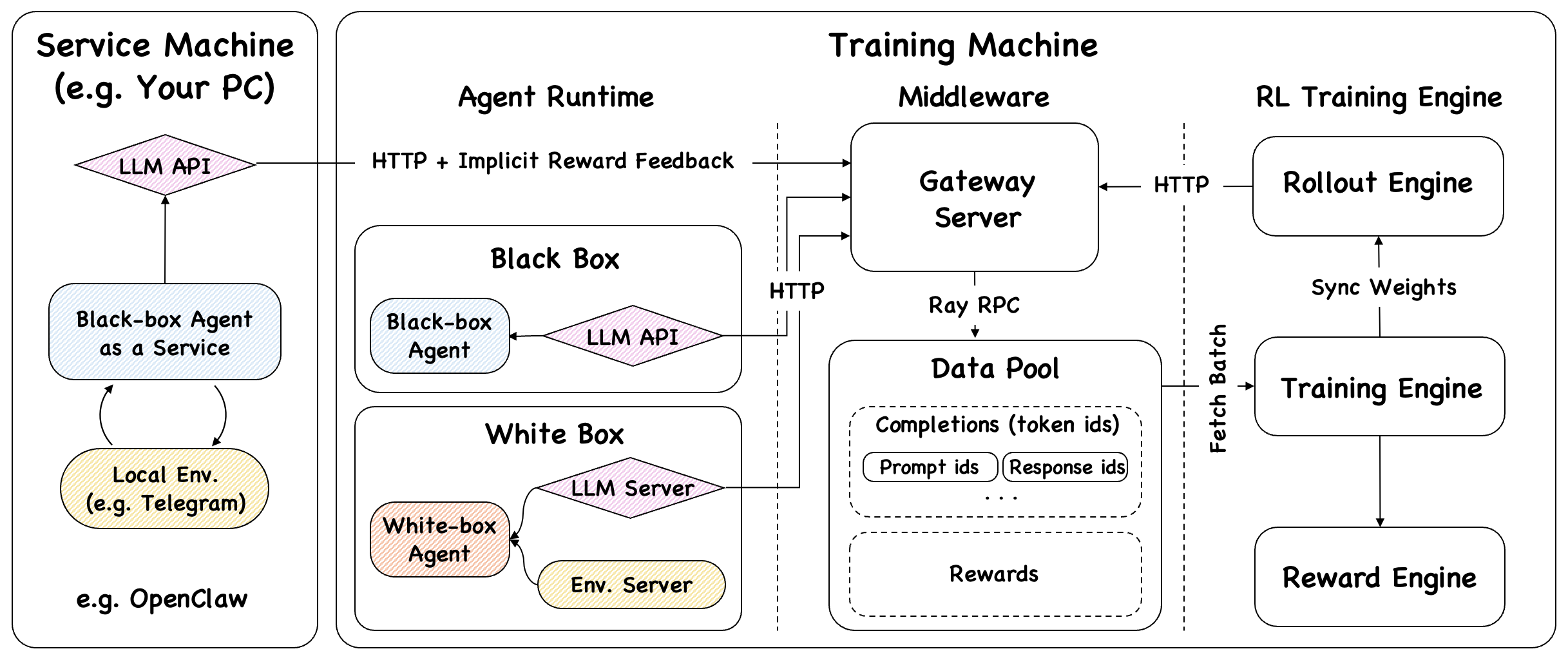
Rollout Engine(生成)与 Training Engine(训练)异步运行,互不阻塞,数据流入 DataPool 后自动拉取批次更新模型。
OpenClaw 在本地机器提供服务,模型训练在高性能服务器上独立进行。无需预置数据集,边服务边训练。
OpenClaw 只需将 base_url 指向 Claw-R1 的 Gateway,框架自动采集交互数据并训练,无需修改 Agent 逻辑。
通过 OpenAI 兼容接口,支持白盒离线、黑盒离线、黑盒在线服务三种运行模式,适配多种部署场景。
Claw-R1 的差异化竞争力来自三点设计的组合,三者共同构成一个完整的闭环,缺一不可。
现有 Agentic RL 框架在接入 Agent 时,普遍需要修改源码或依赖特定 SDK, 对生产级 Agent 系统(如 OpenClaw、AutoGen、CrewAI)而言侵入成本极高。 Claw-R1 通过网络层代理彻底解决这一问题:
| 方案 | 代表框架 | 侵入方式 | 代价 |
|---|---|---|---|
| 修改 Agent 源码 | verl、RL-Factory | 在 Agent 代码中嵌入 Rollout 接口 | 维护成本高,黑盒 Agent 无法用 |
| Python 类包装 | OpenRLHF | 继承 AgentInstanceBase 重写执行逻辑 |
需理解框架 API,不通用 |
| SDK Hook 拦截 | Agent Lightning、ART | 替换 LangChain / OpenAI SDK 的 HTTP 层 | 依赖特定 SDK,换框架即失效 |
| 替换 base_url Claw-R1 | Claw-R1 | 将 LLM 调用重定向到 Gateway | 零改动,任何 HTTP 调用均适用 |
Gateway Server 是标准 FastAPI HTTP 服务,实现完整的 OpenAI 兼容代理。 对 Agent 而言,它只是调用了一个"稍慢一点的 OpenAI API",并不知道每次对话已被送入训练流水线。 实际接入只需一行配置:
对 OpenClaw 而言,只需在配置文件中把 LLM_API_BASE 从 OpenAI 地址改为 Gateway 地址即可。
与 SDK Hook 相比,网络层代理不依赖任何语言或 SDK,
OpenClaw(TypeScript 实现)、运行在独立容器中的 Agent、使用自定义 HTTP 客户端的 Agent 均可零改动接入。
传统 RLVR 训练采用同步循环(生成轨迹 → 计算奖励 → 更新权重 → 再生成), 在生产环境中会导致 Rollout 阻塞训练、训练阻塞服务、真实数据浪费等根本性问题。 Claw-R1 的 Middleware Layer(Gateway + DataPool) 是 Agent Side 与 Training Side 之间的唯一桥梁:
DataPool(Ray Actor)具备四大特性:
与 rLLM DataPool 的核心区别:
| 维度 | rLLM DataPool | Claw-R1 DataPool |
|---|---|---|
| 写入来源 | 批量 Rollout Engine(离线生成) | 真实用户请求(在线服务) |
| 数据性质 | 预设任务的合成轨迹 | 用户真实交互轨迹 |
| 服务状态 | 训练时 Agent 不对外服务 | 训练时 Agent 持续服务 |
| 奖励计算 | 任务结果奖励(Verifiable) | 过程奖励 + 环境反馈 |
rLLM 的 DataPool 是为加速批量训练的缓冲;Claw-R1 的 DataPool 是为了让 Production 服务本身成为训练数据源。
几乎所有 Agentic RL 框架都隐含「训练阶段 ≠ 部署阶段」的假设,这在生产 Agent 场景中有根本性局限:
| 问题 | 表现 |
|---|---|
| 分布偏移 | 训练数据是合成任务,真实用户请求分布不同,导致部署后能力退化 |
| 冷启动 | 新部署模型不了解用户习惯、工具、工作流,需要大量"磨合期" |
| 长尾任务 | benchmark 只覆盖常见任务,真实用户的长尾需求无法通过离线训练覆盖 |
| 环境漂移 | 工具 API 更新、用户行为变化,静态模型无法自适应 |
Claw-R1 的核心场景是个人 Agent 的持续自我进化: 以 OpenClaw 个人助理为例,用户每天通过 Slack / 微信 / 邮件与 OpenClaw 交互, 轨迹经 Gateway 采集 → DataPool → Reward Model 评分 → Training Engine 更新权重, 让 Agent 越用越"懂"这个用户。这要求系统具备三项传统 RL 框架不具备的能力:
三个设计不是独立功能的叠加,而是一个互锁的正向飞轮:
缺少 base_url 即接入 → 黑盒 Agent 无法零成本集成,"真实场景"不成立; 缺少 Middleware Layer → Agent Side 与 Training Side 耦合,退化为传统 RLVR; 缺少 Production 定位 → 失去从真实用户交互中持续学习这一核心价值主张。
Claw-R1 的意义在于:它为 Agent Runtime 时代的强化学习训练 提供了此前从未有过的基础设施。
Agent 的运行环境问题——让 Agent 能在真实消息平台中持续、自主地执行任务。
Agent 的训练框架问题——让模型能以真实环境反馈为奖励信号进行强化学习。
两者结合,正是大模型强化学习第三阶段的核心体现: Runtime RL —— 以真实环境反馈为奖励,让模型学会在现实中行动。
在这种范式下,AI 不再只是学习生成文本,也不再只是完成孤立的可验证任务,而是学习 如何在真实 Agent Runtime 中持续、稳定地完成复杂任务。
随着 Agent 技术的发展,大模型系统正逐渐演化为:
提供执行环境
提供学习机制
提供训练基础设施
这些技术的结合,很可能将成为下一代 Agentic AI 系统的基础架构。 而 Claw-R1,正是这一方向上的一次重要探索。
如果本项目对您的研究有所帮助,请考虑引用: